クラウド関係のメモ (KVSとかDHTとかその辺)
Google File System
- pure p2pじゃない
- どっちかっていうと,winMX
- 単一のマスターノードがファイルの位置とかを知ってる
- クライアントは,検索したいときマスターノードにファイルの位置を聞く
- マスターノードがファイルの位置(チャンクサーバのアドレス)を返す
- クライアントがチャンクサーバが通信してファイルのやり取りをする
- データの一貫性は無視
dfltweb1.onamae.com – このドメインはお名前.comで取得されています。
世界中のWebのページを格納するには巨大な容量のファイルシステムが必要となりますが、彼らはそれを自分たちで、Scale-outする分散ファイルシステム
Google File System(GFS)技術メモ — ありえるえりあ
- 構成ノードは、マスターノード、チャンクサーバ、クライアントの3種類です。
- 単一のマスターノードが、ファイルのディレクトリツリーの状態管理、ロック管理、チャンク(下記参照)の位置管理を担います。
- 複数のチャンクサーバがマスターノードの下にぶら下がります。各ファイルは固定長のチャンクに分割されて、チャンクサーバのストレージに保存されます。各チャンクは、複数のチャンクサーバに複製されます(レプリケーション)。
- クライアントは、GFSを利用するアプリと、それにリンクされるライブラリです。ライブラリはネットワークRPCを隠蔽したAPIを提供します。アプリ側の視点で見ると、APIを通じてGFS上にファイルを作ったり、読み書きしたりします(*注4)。GFS側の視点で見ると、アプリにリンクされたライブラリが、マスターやチャンクサーバとGFS通信プロトコルで話をします。
- チャンク(ファイルのコンテンツの断片)自体の転送は、クライアントとチャンクサーバの間で直接行われます(マスターは転送に介在しません。マスターは、クライアントにチャンクサーバの位置を教えるだけです)。
[分散処理]処理を高速化する唯一の解 | 日経 xTECH(クロステック)
GFSでは,ファイルは64Mバイトのブロック(チャンク)に分割され,3台のサーバーに重複保存される。この3台の組み合わせは一定ではない。つまり,1個のファイルが最低でも数十台のサーバーに重複して並列保存されるのだ。こうして,データI/Oの高速化と冗長化を図っている。分散保存されているデータをつなぎ合わせて処理するのがMapReduceの役割となる。
Hadoop、hBaseで構築する大規模分散データ処理システム (1/2):CodeZine(コードジン)
Google File Systemは巨大なファイルを扱うのに特化されていますが、小さいファイルの大量の読み書きには向いていません。しかしWebページなどの情報を扱うには、構造化された小さいデータに対してデータベース的にアクセスしたいという要求があります。BigTableはそのような要求を満たすために作られた分散データベースです。
Hadoopで、かんたん分散処理 - Yahoo! JAPAN Tech Blog

MapReduce
MapReduce - Wikipedia
MapReduce は、ある種の問題について、多数のコンピューター(ノード)の集合であるコンピュータ・クラスターを用いて並列処理させるためのフレームワークのひとつである。
radiumsoftware.com
MapReduce の動作を説明するには,論文の冒頭に挙げられている単語カウントの例を用いるのが分かりやすくてよい。ここでは,膨大な文書 ― 例えば「ウェブ上のテキスト全て」などから,単語の出現頻度を調べたいとする。


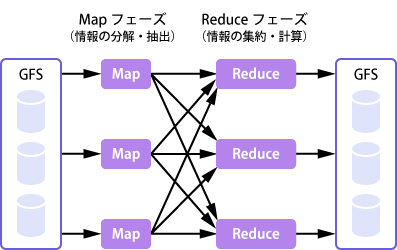
BigTable
- メモリ上で保存
- ACIDより応答性
グーグルは“異形”のメーカー。ここが違う10個のポイント | 日経 xTECH(クロステック)
BigTableは、データがどのサーバーのどの行に保存されているかというメタデータや、最近書き込まれたデータなどを、サーバーのメモリー上に保存する。データの保存場所としてハードディスクを使用するGFSよりも、データ処理の応答性が高い。BigTableは現在、GmailやGoogle Mapsのような、高い応答性能を求められる大規模アプリケーションの基盤として広く使われている。
(中略)
厳格なトランザクション処理を省いたBigTableや、「エラーを無視する」Sawzallは、「ACID」を重視するエンタープライズシステムとは相容れない存在に見受けられる。ACIDとは、原子性(Atomicity)、一貫性(Consistency)、独立性(Isolation)、耐久性(Durability)の頭文字を組み合わせたもの。RDBは必ずACID特性を満たすように設計されている。
memcached
「foo」というキーに「bar」という3バイトのデータを非圧縮/無期限で格納 $ telnet localhost 11211 Trying 127.0.0.1... Connected to localhost.localdomain (127.0.0.1). Escape character is '^]'. set foo 0 0 3 (保存コマンド <キー> <フラグ> <有効期間> <サイズ>) bar (データ) =>STORED (結果) get foo (取得コマンド <キー>) =>VALUE foo 0 3 (データ) =>bar (データ)
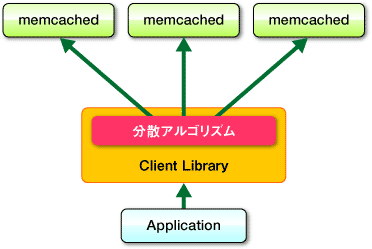
memcachedの位置は↑図みたいな感じ
memcached | feedforce Engineers' blog
オブジェクトをメモリにキャッシュするデーモン。
動的ページを持つウェブアプリケーションの裏側で動くデータベースへの負荷を軽減させることを目的にデザインされている。
(中略)
- セッションストア
- DBへのクエリ結果のキャッシュ
- アプリケーションレベルのオブジェクト共有(静的インスタンス)
Amazon Dynamo
- メモリ上で保存
- ACIDより応答性
- memcached + コンシステントハッシュ法(0-hopなDHT.要するに各ノードがネットワークに参加してる全ノードのアドレスを知ってる) + eventual consistency(一貫性保持http://www.hyuki.com/yukiwiki/wiki.cgi?EventuallyConsistent)+ Service Level Agreements
http://www.shudo.net/publications/cloud-scaleout-20081219/shudo-cloud-scaleout-20081219.pdf
- Amazon の内部で使われている。
- ショッピングカート。
- Amazon Web Services (AWS) のSimpleDB は、おそらくDynamo で運用されている。
(中略)
- 一貫性
- eventual consistency
- 不整合が起きた場合、データに付いてるvector clocks[Lamport1978] を手がかりに、アプリ側で解決する。
Microsoft Windows Azure
- ACIDより応答性
- memcached + DHT
http://www.cs.waseda.ac.jp/gcoe/jpn/publication/symposium/img/Lec4-shudo.pdf
両方向版Chord とでも呼ぶべきもの。
http://www.java-users.jp/contents/events/ccc2009spring/materials/G-1.pdf(Cloudの技術的特徴について)
Windows Azureでは、File SystemのレベルではなくData StorageのレベルでReplicaが導入されている。また、Fail-overについて、いくつかのシナリオが用意されているので、それを見ておこう。
(↑Azureの多重化・冗長化の話が書いてある.便利)
ちょっとまとめ
ddd
http://www.iij.ad.jp/development/iir/pdf/iir_vol04_cloud.pdf
dddはdistributed database daemonの略称で,IIJバックボーンを流れる膨大なトラフィックを解析するために作られました.
(中略)
数百億超の大量のフロー情報レコードを保持し,様々な条件で高速にデ0田を抽出したり,集計したりすることができます.

Kai
第1回 Kaiとは? ─Kaiのコンセプトとメカニズム:分散Key/Valueストア,Kaiを使ってみよう!|gihyo.jp … 技術評論社
Kaiとは,分散型のKey/Valueストアです。Amazon.comが2007年に発表したDynamoというシステムに触発されて,そのオープンソース版として開発されています。Kaiをバックエンドに据えてWebサイトを構築することで,高いスケーラビリティやアベイラビリティを実現できます。 2009年5月には,gooホームのバックエンドに導入され,運用実績も高まってきました。
Rakuten On-Memory Architecture (楽天 ROMA)
- 複数マシンから構成されるオンメモリストレージ
- memcached + コンシステントハッシュ法
http://www.nogutetu.com/2007/11/os.html
The Overall Architecture of ROMA
本を読む 楽天でROMAとfairyの話を聞いてきた
大規模分散処理向けの国産“ウェブOS”をRubyで開発中 − @IT
まつもと氏は、Romaのコンセプトについて「CPUやネットワークに比べてハードディスクの速度は上がっていない。メモリ上にデータを保持し、マシンを大量にネットワーク上にばらまいたら、そちらの方が速い」と説明する。「単にメモリを分散するだけならmemcached(注:大規模BlogサイトLiveJournal.comの性能向上のために作られたオープンソースの分散キャッシュ・システム)でいいと思うかもしれないが、マシンを1000台並べ、そのうち1台が壊れても止まらない信頼性と一貫性を確保することを考えると、より高度なアイデアが必要。ただしその分、実用化までには壁がありそうだ」(まつもと氏)。Romaの応用として、巨大セッションを保持するコンテキスト基盤などを考えている。Romaの技術的な位置づけは、米グーグルの「GFS」(Google File System)、米ヤフーの「Hadoop」(ハドゥープ)、米オラクルの「Coherence」(コヒーレンス)、米アマゾンの「Dynamo」(ダイナモ)など大規模分散ストレージ技術と似ている。楽天技術研究所代表の森正弥氏によれば「特にDynamoに位置づけが近い」とのことである。
一方のFairyは並列処理向けの技術で、MapReduce(注:グーグルが分散処理の基盤技術として利用することで知られる並列処理向けアルゴリズム)のRuby実装として検討を始めたもの。大規模並列処理の負荷分散への適用を狙う。「現在は、並列処理よりも負荷分散に主眼を置いて研究を進めている」(森氏)。
ObjectGrid
http://marulec.cloud-market.com/archive/2007/20080218/20080218_2.pdf
(結構詳しく書いてある)
JBoss Cache
全景
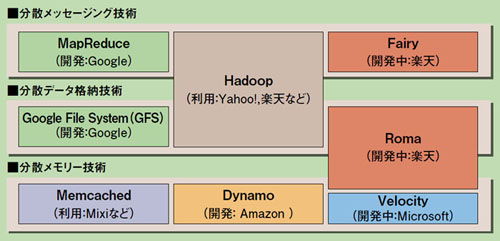
@IT Special PR: 複数のメモリ空間を横断的に統合する“ミドルウェア・データグリッド”の先進的テクノロジー
グーグルは“異形”のメーカー。ここが違う10個のポイント(8ページ目) | 日経 xTECH(クロステック)
Amazon DynamoやAzure Storageは、データの主たる保存先をサーバーの物理メモリーとすることで、システムの応答性を向上するというアプローチを採用している。
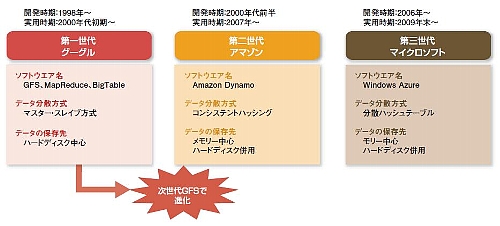
http://www.slideshare.net/mkyamaya/s10(クラウドのプレゼン資料.全171P)
クラウドの技術的特徴とデータセンタ
クラウド・コンピューティングの定義 : 産地偽装クラウドにだまされないために - ベテランIT営業が教える「正しいITの使い方、営業の使い方」 - ZDNet Japan